스트림이란?
스트림(Stream)의 정의
Java8부터 추가된 컬렉션(배열 포함)의 저장 요소(Element)를 하나씩 참조해서 람다식(함수적-스타일, functional-style)으로 처리할 수 있도록 해주는 반복자

=> 기존엔 포문을 돌려서 words라는 String 컬렉션을 처리할 때 반복문을 사용해서 엘레먼트를 하나씩 접근해서 처리했었음.
=> Stream 방식을 사용하면 word를 스트림으로 바꾼 후 (words.stream()) filter 함수를 적용해 파라미터로 바로 람다식이 들어간다. 필터링한 후 카운트를 해주게 된다.
=> words의 엘레먼트가 굉장히 많을 경우 parallelStream을 통해 병렬 처리가 가능하다. 병렬 처리는 cpu의 코어를 이야기한다. 컬렉션을 4개로 쪼개서 코어 4개에 할당한다음 최종적으로 합산하는 과정을 거친다.
=> 기존과 Stream의 차이점은 한마디로 “자동화”이다. 기존 반복문을 통한 처리는 한땀 한땀 처리를 하지만 Stream을 사용하면 로직만 람다로 던져주면 내부적으로 JVM이 알아서 결과를 추출해주는 것이 스트림이다.
스트림 파이프라인
파이프라인, Pipeline
유닉스에서 유래된 개념으로, 어떤 작업을 할 때 최종적인 결과를 얻기까지 (스트림소스를 가공하는 과정을 거쳐) 과정 하나가 처리되면 그 결과를 다음 과정의 파라미터로 넘겨주고, 또 다시 처리 후 다음 과정의 파라미터로 넘겨주는 중간 과정을 거치고 후에 최종 결과물을 만들어낸다.
여러개의 스트림이 연결되어 있는 구조

파이프라인에서 최종 처리를 제외하고는 모두 중간 처리 스트림
스트림 작업 흐름
- 스트림을 생성한다. (스트림으로 변환시킨다.)
- 초기 스트림을 다른 스트림으로 변환하는 중간 연산을 지정한다. (중간 연산 파이프라인을 통해 데이터를 계속 흘려보낸다.) (생략 가능하다.)
- 종료연산을 적용해서 결과를 산출한다.
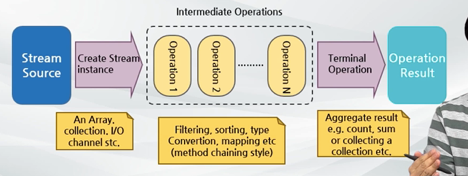
반복에서 스트림으로 전환
- 컬렉션을 처리할 때 일반적으로 요소를 순회하면서 처리한다.
- 스트림을 사용하면 데이터를 선언적으로 처리할 수 있다.
<예제>
단어 리스트에서 공백을 제거하고 12글자 이상인 단어의 개수를 확인
// old school (기존)
int count = 0;
for (String w : words) {
if (w.trim().length()>12) count++;
}
// modern (스트림 사용)
long count = words.stream()
.map(w -> w.trim())
.filter(w -> w.length() > 12)
.count();
스트림 특징 - 반복의 내재화
- 외부반복 : 반복을 명시적으로 수행. 코드가 가독성이 떨어질 수 있다.
- 내부반복 : 반복되는 코드는 외부로 노출되지 않고, 내부에서 반복을 수행한다. (JVM을 통해 자동적으로 반복 수행). 개발자가 하는 일은 반복 로직(알고리즘)을 넣어주는 것이다. (함수형 처리 방식)
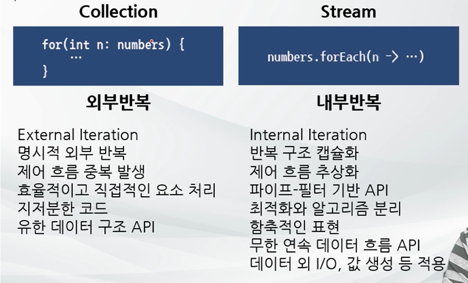
컬렉션 vs. 스트림
같은 점
- 컬렉션과 스트림 모두 연속된 요소 형식의 값을 저장하는 자료구조의 인터페이스를 제공함
- 둘 다 순서에 따라 순차적으로 요소에 접근함
=> 대부분의 데이터는 컬렉션으로 다뤄진다. 예를들어 엑셀은 한 로우가 컬렉션으로 들어간다. 모든 테이블형 데이터는 반복을 통해 컬렉션이 만들어진다. 컬렉션은 일반적으로 풀스캔을 하여 처리된다.
다른 점
- 컬렉션 : 각 계산식을 만날 때마다 데이터가 계산됨
- 스트림 : 최종 연산이 실행될 때 데이터가 계산됨 (로직만 던져주면 나머지는 내부에서 자동적으로 처리. 스트림은 항상 최종 연산이라는 것이 필요하다. 이 전에는 데이터가 완성되지 않고 중간 과정일 뿐이다.)
다른 점 (데이터 접근 측면)
- 컬렉션 : 직접 데이터 핸들링
- 스트림 : 계산식을 JVM에게 던진다. 즉, 데이터에 접근하는 방식이 추상화되어있다.
다른 점 (데이터 계산 측면)
컬렉션 :
- 작업을 위해서 Iterator로 모든 요소를 순환해야 함.
- 메모리에 모든 요소가 올라가있는 상태에서 요소들을 누적시키며 결과를 계산함.
- 그렇기 때문에 메모리 사용량이 늘어남. (eager loading이라 한다. 모든 데이터를 메모리에 올려서 사용)
스트림 :
- 계산식(알고리즘)을 미리 적어두고 계산시에 람다식으로 JVM에 넘김
- 내부에서 요소들을 어떻게 메모리에 올리는지는 관심사가 아님 (블랙박스) (그것은 JVM이 최적화된 내부적인 알고리즘에 의해 알아서 처리한다.)
- 메모리 사용량이 줄어듦 (lazy loading)
예) 동영상 시청시 몇 기가가 되는 동영상을 전부 메모리에 올려서 플레이 하는것은 아니다. 동영상의 일부분만 메모리에 올리고 처리하고, 다시 올리고 처리하고 하면서 우리가 볼 수 있는 것이다. 그래서 동영상을 전체 다 하드디스크에 다운받지 않아도 네트웍에서 조금씩 다운받아가며 시청 가능하다. 데이터의 스트림도 이와 같은 개념이다.
=> 스트림이 좋은 이유는 빅데이터 때문이다. 더 유리하고 스트림으로 처리할 수 밖에 없기 때문.
스트림 종류
- java.util.stream 패키지의 Stream API
- BaseStream 인터페이스는 모든 스트림에서 사용할 수 있는 공통 메소드들이 정의
- Stream 클래스는 객체타입의 요소 처리
- IntStream, LongStream, DoubleStream은 각각 기본 타입인 int, long, double 요소 처리

=> Stream 클래스는 제너릭 클래스다. 그래서 Stream에서 타입 <T>를 받아 사용한다. 하지만 기본 타입이 올 수 없기 때문에 숫자를 처리하는 스트림을 별도로 마련해놓은것이 IntStream, LongStream, DoubleStream이다. wrapper로 Stream<Integer> 할수는 있지만 내부적으로 Integer이 int로 언박싱이 일어나고 다시 반환될땐 Integer로 박싱되면서 소모적이다.
스트림 생성 방법
다양한 방식의 스트림 생성 방법 제공
- Collection : 콜렉션객체.stream(), parallelStream()
- Files : Stream<String> Files.lines() (=> 특정한 텍스트파일을 라인 바이 라인으로 읽어 스트림으로 만들어준다.)
- Arrays : Arrays.stream(*)
- Random : Random.doubles(*), ints(*), longs(*) (=> 랜덤한 숫자를 연속적으로 스트림으로 만든다. 무한대기 때문에 최초 100개, 최초 10000개까지만 만들어라 라는 식으로 제한을 준다.)
- Stream :
- Stream.of(*)
- range(start, end), rangeClosed(start, end)
- IntStream, LongStream에서 제공
- Stream.generate(Supplier<T> s) (무한스트림)
- Stream.iterate(T seed, UnaryOperator<T> f)

스트림 생성 예제
// Stream의 Static 메소드 of 사용
Stream<String> stream = Stream.of(“Java8”, “Lambda”, “Stream”, “Nashorn”);
// 엘레먼트를 of 함수를 이용해 바로 만들어줌
Stream<Integer> values = Stream.of(1, 2, 2, 3, 3, 3, 4, 2);
// random함수를 이용한 무한 스트림 생성
Stream<Double> = Stream.generate(() -> Math.random());
// int[] 을 IntStream으로 변환
int[] numbers = {2, 3, 4, 5, 6, 7};
IntStream intStream = Arrays.stream(numbers);
// Stream static 메소드 iterate 사용
Stream<Integer> iterate = Stream.iterate(0, n -> n+2);
스트림 : 중간연산과 최종연산
- 단말 연산을 스트림 파이프 라인에 실행하기 전까지는 아무 연산도 수행하지 않는다. (Lazy)
- 모든 중간 연산을 합친 다음 최종연산에서 한번에 처리한다.
- filter, map, limit는 서로 연결되어 파이프 라인을 형성한다.
- collect로 마지막 파이프 라인을 수행 후 완료한다.
menu.stream()
.filter(d -> d.getCalories() > 300)
.map(Dish::getName)
.limit(3)
.collect(Collectors.toList()); //[pork, beef, chicken]=> menu라는 리스트를 .stream()으로 스트림화한다.
.을 통해서 계속 연산을 하는데, 이를 메소드 체이닝이라고 한다.
menu라는 ArrayList를 스트림화하고 이 메뉴 안의 엘레멘트의 칼로리가 300이 넘는 애들을 필터링을 한다.
filter을 거치면 필터링이 된 새로운 300칼로리 이하의 요소들로 이루어진 새로운 스트림을 만든다. (스트림에서는 모든 중간연산을 거칠때마다 새로운 스트림이 생긴다.)
map은 각 엘레먼트마다 특정한 함수를 적용시킨다. Dish 객체의 이름만 추출(getName) 한다. 그래서 String만 가지게 되는 stream으로 바뀌게 된다.
limit(3)을 거치면서 마지막 3개만 추출하게 되고 collect 함수에서 다시 리스트로 바뀌게 된다.
이러한 중간연산의 저수준의 알고리즘을 JVM이 알아서 처리해주는 것이다. 그래서 속도가 빨라지는 것이다.
ThinkPoint
함수형 프로그램이란? 장단점은?
함수형 프로그래밍은 자료 처리를 수학적 함수의 계산으로 취급하고 상태와 가변 데이터를 멀리하는 프로그래밍 패러다임의 하나이다.
명령형 프로그래밍에서는 상태를 바꾸는 것을 강조하는 것과는 달리, 함수형 프로그래밍은 함수의 응용을 강조한다.
함수형 프로그래밍은 1930년대에 계산 가능성, 결정문제, 함수정의, 함수응용과 재귀를 연구하기 위해 개발된 형식체계인 람다 대수에 근간을 두고 있다.
다수의 함수형 프로그래밍 언어들은 람다 연산을 발전시킨 것으로 볼 수 있다.
'Programming > Java' 카테고리의 다른 글
| [Java9 프로그래밍] 17. 입출력 처리하기 (0) | 2020.03.30 |
|---|---|
| [Java9 프로그래밍] 16. 스트림 활용과 Optional (0) | 2020.03.30 |
| [Java9 프로그래밍] 14. 제네릭과 컬렉션 (0) | 2020.03.29 |
| [Java9 프로그래밍] 13. 예외 처리 (0) | 2020.03.21 |
| [Java9 프로그래밍] 12. 람다 표현식 (0) | 2020.03.21 |